
Arthur Queffelec
Wednesday, April 29, 2026 | 9 minutes
Agentic Philosophical Chamber
Introduction
Hi there!
I wanted to build something playful with LangGraph, but I did not want it to be another app that tries to solve a productivity problem (there are enough of those out there). The idea that stuck was a philosophical chamber: you ask a question, a small cast of AI agents debate it, and the discussion is turned into a live argument map instead of a wall of text.
That framing gave me a useful constraint. If the agents were going to disagree, challenge each other, and occasionally produce bad reasoning, I needed more than role prompts. I needed a graph that could track the state of the debate, decide who speaks next, send turns through review, and keep the whole run inspectable.
That is what this project became: a fun LangGraph experiment where a philosophical question is transformed into a structured multi-agent debate, complete with an evolving argument map.
Why LangGraph Fits This Project
This project is a good fit for LangGraph because the chamber is naturally a state machine.
At any point in the run, the system needs to know the current question, round, state of the debate, which primary speakers have already spoken, whether a judge has flagged a problem and whether the crowd event should trigger. That is not a simple prompt pipeline. It is shared state moving through a graph.
LangGraph made that explicit. Instead of hiding orchestration inside a giant loop, I could model the chamber as nodes and conditional edges. Each node updates a slice of state, and the next step depends on the result of that state transition. That structure made the project easier to reason about, easier to debug, and much easier to visualize.
The Chamber Starts With an Argument Map
The output of the debate is not just text. Every turn is supposed to add structure to an argument map.
The map starts from a single contention node, then expands with premises, objections, rebuttals, support links, attack links, and inference-level undercuts. That matters because it changes the quality of the interaction. The agents are not only trying to sound plausible. They are being asked to attach their claims to an existing structure.
This pushes the debate in a more disciplined direction. A critic should not just complain in general terms. The critic should attack a specific node. An advocate should strengthen an existing conclusion. An auditor should react to weak inferences. Even when the language model is improvising, the shape of the output has to fit the map.
The Chamber as a Graph
The chamber is organized around a handful of graph nodes rather than around a monolithic debate loop.
The run begins with a moderator node that turns the user question into a clean debate contention. From there, the graph moves into the primary debate cycle: Advocate, Critic, and Sophist each contribute to the map. After each primary speaker, the graph does not immediately continue to the next speaker. It first routes into a review step.
That review step is the real heart of the project. The graph checks whether the latest claims should trigger an Auditor response, an Ethicist response, or neither. If one of those judge agents needs to intervene, the graph temporarily detours through that node before returning to the main speaking loop.
There are also two nodes that make the chamber feel less mechanical. A crowd dice roll can trigger a Crowd Member turn, which injects a more practical or public-facing concern. A round-advance node resets the per-round speaker bookkeeping and decides whether the debate should continue or end in a moderator summary.
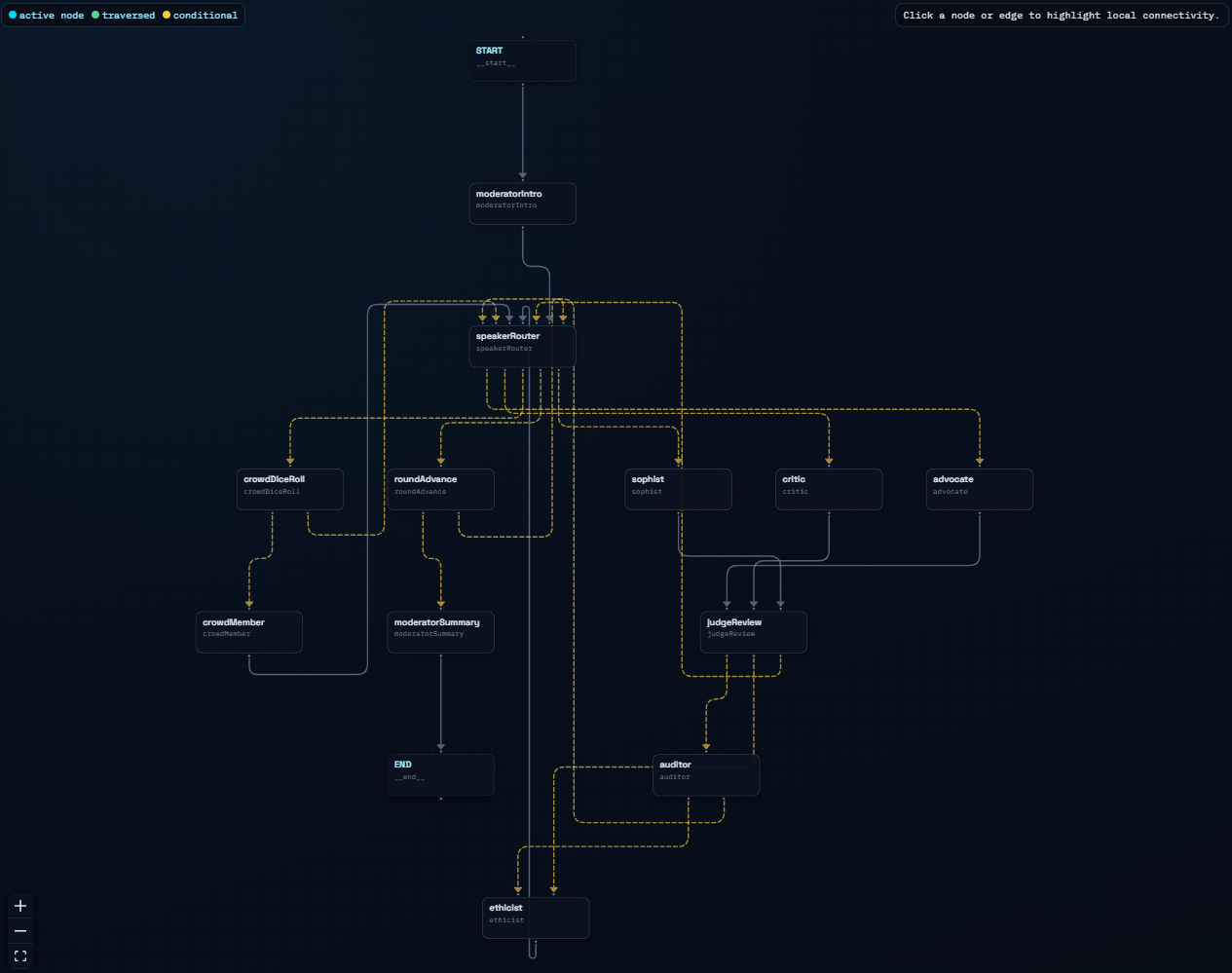
How Speaker Routing Stays Interesting
One thing I wanted to avoid was making the debate feel completely scripted. If the sequence were always identical, the chamber would become predictable very quickly. At the same time, fully random routing would make the system feel noisy and uncontrolled.
The compromise was to make routing weighted rather than fixed.
Each round still guarantees that the three primary speakers all get a turn, which keeps the debate balanced. But within that constraint, the next speaker is chosen through weighted routing that considers the current map and the recent turn history. If the map needs more support structure, the Advocate becomes more likely. If the map lacks attacks, the Critic gains weight. The Sophist adds a different rhetorical pressure to the system, and some small randomness keeps repeated runs from collapsing into the exact same sequence.
That combination turned out to matter a lot. It makes the debate feel alive without letting it drift too far away from the structure I want the graph to maintain.
The Agents
Although the chamber has several characters, I think the clearest way to understand them is by function rather than by personality.
Moderator
The moderator frames the debate by rewriting the user question into a concise contention at the start, then closes the run with a final summary after the rounds are complete. In other words, the moderator defines the scope of the argument and then helps the reader interpret the outcome.
Primary Speakers
The Advocate, Critic, and Sophist form the main debate loop.
The Advocate tries to strengthen conclusions by adding support. The Critic looks for concrete objections and weak points. The Sophist is intentionally a little different: it adds persuasive pressure to the debate and often pushes the map in directions that are rhetorically interesting, not only strictly balanced. Together, these three roles create most of the map growth.
Judge Layer
The Auditor and Ethicist are not just additional speakers. They are a review layer.
After every primary turn, the chamber can ask two judge passes to inspect the new claims. The Auditor looks for problems such as fallacies, manipulation, bias, or unsupported claims. The Ethicist looks for concerns such as harm, fairness, dignity, duties, or rights conflicts. If either layer finds a real issue worth reacting to, the graph routes through the corresponding agent before continuing.
This judge layer is one of my favorite parts of the project because it turns the chamber into something more than a round-robin conversation. It becomes a debate with procedural friction. Claims can be challenged not only by opposing speakers, but by the rules of the chamber itself.
Crowd Member
The Crowd Member is a small random event that adds practical concerns from outside the main expert roles. It is a minor feature in terms of code, but it adds a nice texture to runs because it can suddenly steer the map toward real-world consequences or common-sense objections.
Constrained Generation Matters More Than Character Prompts
If you look at the project from a distance, it might seem like the hard part is inventing agent personalities. In practice, the more important engineering choice was constraining what each turn is allowed to produce.
Each speaker is asked to return structured content for the argument map, not a free-form paragraph. The output has to be shaped in a way that can be parsed and merged into the existing map. That means each turn becomes actionable state, not just text for the reader.
This is also why the project stays coherent longer than a simple multi-agent chat. The map acts as a memory and a structure. Agents are repeatedly pushed back toward existing nodes, explicit relations, and focused contributions. The chamber still gets weird sometimes, which is part of the fun, but it is weird within a scaffold.
Making the Run Inspectable
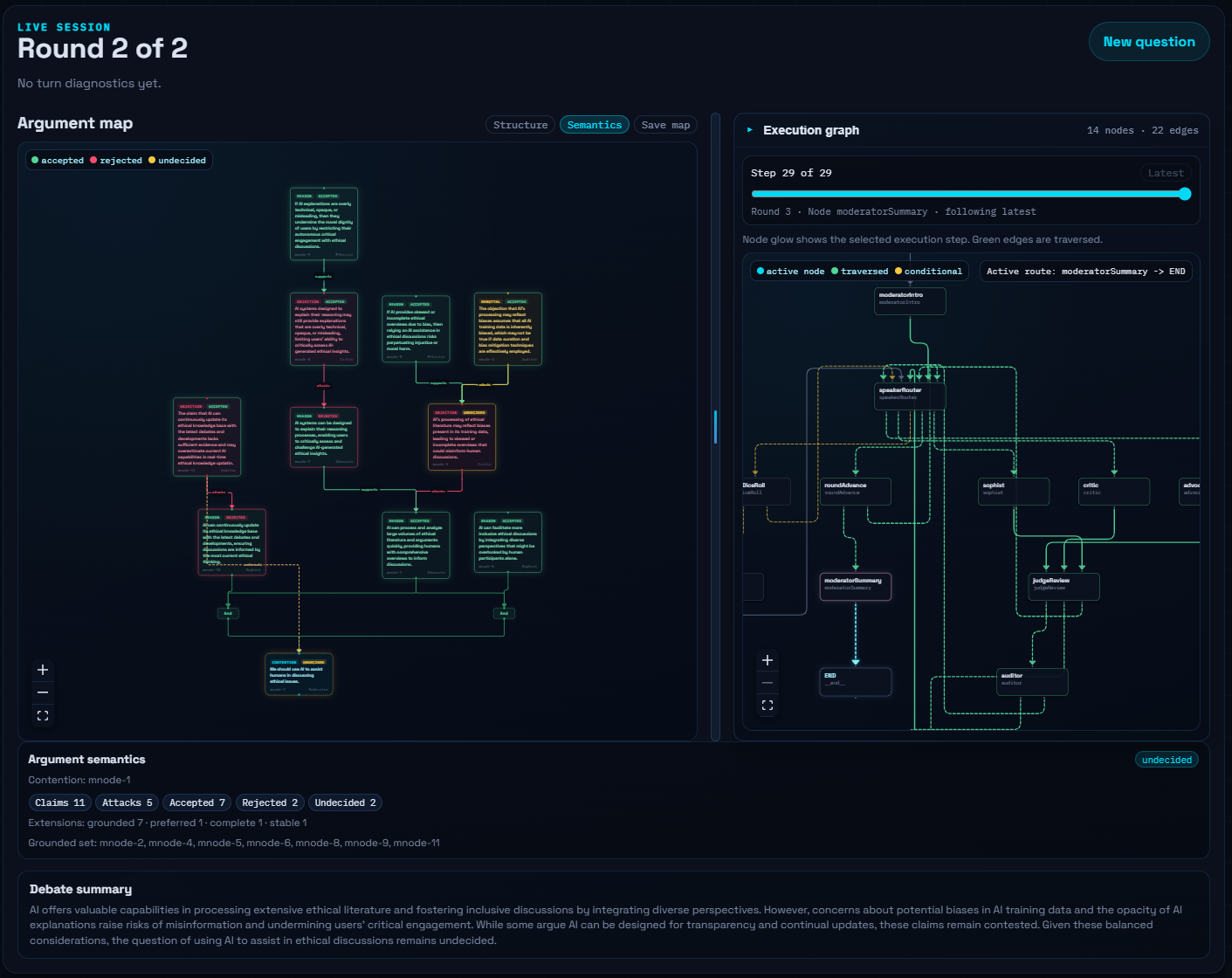
I did not want the debate to feel like a black box. If the whole point of using LangGraph is orchestration, then the orchestration should be visible.
So the run is streamed as evolving state snapshots. Alongside the argument map itself, the UI can show which node just executed, what route was chosen, and how the run moved through the graph. That makes it possible to inspect the debate not only as content, but as a process.
I think this is one of the most satisfying parts of the project. You can watch the chamber produce arguments, but you can also watch the control flow that led to those arguments. For experimentation, that is extremely useful. When a run behaves oddly, I do not have to guess what happened. I can see which node fired, whether a judge intervened, and how the graph advanced.
A Few Debate Runs
I tried the chamber on a few deliberately strange or provocative questions because they produce clearer behavior than safe benchmark prompts.
The Dog Petting Problem
Should humans be allowed to pet dogs without explicit permission from the dog?
This question is interesting because it sounds silly at first, but it forces the chamber to negotiate consent, interpretation, animal behavior, and practical norms.
The AI Agent Rights Problem
Should AI agents be given rights?
I like this question because AI agents are debating their own rights.
The Simulation Hypothesis
Could we be living in a simulation?
This is probably the most on-theme question for the project because the agents themselves are participating in a simulated chamber while debating a simulated world.
Practical Limits
The project runs in the browser, uses a bring-your-own OpenAI API key flow, and supports OpenAI models only.
If I extend the project later, I would like to support additional providers. But for the current version, keeping the runtime narrow helped me focus on the graph itself.
Demo
You can check the demo out live here
Future Improvements
This project is still an early experiment, and there are a few directions that feel especially promising.
- Add richer routing policies so the chamber can react not only to speaker history, but also to specific map patterns or unresolved tensions.
- Give judge interventions more memory so the Auditor and Ethicist can build on repeated concerns rather than reacting in isolation.
- Allow live user interaction during a run, such as pausing the chamber, asking for clarification, or injecting a challenge.
- Expand observability so it is easier to compare runs, inspect costs, and understand why one route was chosen over another.
- Support more model providers once the core LangGraph behavior feels stable enough to compare across runtimes.
Call to Action
If you want to try it yourself, take a look at the code, run the project locally, and give the chamber a question that is weird enough to stress it a little. That is usually when it becomes the most interesting.
License
My code is open source under the MIT License.